Data Structures Behind Git
The underlying data structure of a Git repository is just a directed acylic graph (DAG). Not only the core idea is simple, the implementation can be easily inspected in the .git directory. Let’s break it down.
If Git is a graph, what are the “nodes”?
There are three types of “nodes”, also known as Git Objects - Blobs, Trees and Commits. The article will run through an example usage of Git so that we can observe how each of them is created.
Empty Git repository
After initializing an empty Git repository, the .git directory is shown below. For the rest of the article, our focus will be on the .git/objects directory.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
.
|____branches
|____config
|____description
|____HEAD
|____hooks
| |____applypatch-msg.sample
| |____commit-msg.sample
| |...
|____info
| |____exclude
|____objects <--- Our focus
| |____info
| |____pack
|____refs
| |____heads
| |____tags
Git Object - Blob
We will create a new file and add it to staging.
1
2
echo "Hello World" > hello.txt
git add hello.txt
Now we can find a new directory and file in .git/objects.
1
2
3
4
5
6
7
.
|____objects
| |____55
| | |____7db03de997c86a4a028e1ebd3a1ceb225be238
| |____info
| |____pack
...
Note that the concatenation of the directory name and file name is a 20-byte hash digest.
If we inspect the file, we will see that it is not a human-readable format.
1
cat .git/objects/55/7db03de997c86a4a028e1ebd3a1ceb225be238
1
xKOR04bH/IAI
This is because Git stores content in a compressed binary format. If we uncompress with the appropriate algorithm, the contents can be seen as below. This Git Object is indicated to be a 12-byte Blob with data being Hello World\n.
1
blob 12Hello World
Remember the 20-byte hash digest? To produce it, Git has actually run SHA-1 on the uncompressed data shown above. In other words, a Blob is simply contents of one file and is identified by SHA-1 hash of its contents.
Note that our Blob does not contain any information about the file name hello.txt.
Inspecting Git Objects
Convenient to us, Git provides APIs to inspect the compressed data in Git Objects.
1
2
3
4
5
# Inspect the type of Git Object
git cat-file -t 557db
# Inspect the content of Git Object
git cat-file -p 557db
1
2
3
4
5
# Type of Git Object
blob
# Content of Git Object
Hello World
Git Object - Tree
Now that we understand what a Blob is, let’s create a new commit.
1
git commit -m "First commit"
Looking at .git/objects again, there are two new Git Objects created.
1
2
3
4
5
6
7
8
9
.
|____objects
| |____55
| | |____7db03de997c86a4a028e1ebd3a1ceb225be238
| |____97
| | |____b49d4c943e3715fe30f141cc6f27a8548cee0e <-- New file 1
| |____c5
| | |____5df28adf8320cc4d15637b82e8a0b13422d955 <-- New file 2
...
If we inspect 97b49 with cat-file, the Git Object type and its contents are shown below.
1
2
3
4
5
# Type of Git Object
tree
# Content of Git Object
100644 blob 557db03de997c86a4a028e1ebd3a1ceb225be238 hello.txt
It can be seen that this particular Git Object is a Tree. More specifically, it has a pointer to a Blob with hash digest 557db while naming it hello.txt. It also states that the file has a 644 permission.
In the example, the Tree has one Blob pointer but in reality it can have multiple Blob pointers and even other Tree pointers. In other words, a Tree simply contains pointers to other Git Objects and is identified by the SHA-1 hash of its contents.
Excluding the file names from Blobs is an intentional optimization by Git. If there are two files with duplicate content but different names, Git’s representation will be multiple pointers pointing to the same Blob.
Git Object - Commit
There is still one more Git Object. If we inspect c55df with cat-file, the results are shown below.
1
2
3
4
5
6
7
# Type of Git Object
commit
# Content of Git Object
tree 97b49d4c943e3715fe30f141cc6f27a8548cee0e
author yarkhinephyo <yarkhinephyo@gmail.com> 1652402598 +0800
committer yarkhinephyo <yarkhinephyo@gmail.com> 1652402598 +0800
It can be seen that a Commit contains a pointer to a single Tree encompassing the contents of the commit and other bookkeeping details (such as author and timestamp). Similar to other Git Objects, a Commit is also identified by the SHA-1 hash of its contents.
Putting it together - Directed acyclic graph
1
2
3
echo "Hello World" > hello.txt
git add hello.txt
git commit "First commit"
Considering all the pointers, the Git Objects resulting from these commands can be represented as a graph.
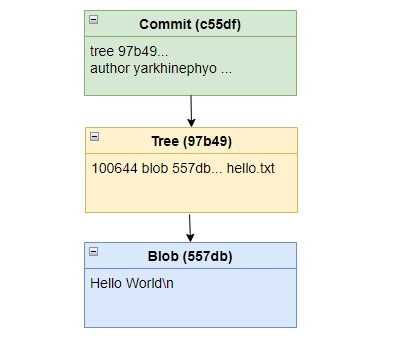 DAG after first commit - Diagram by author
DAG after first commit - Diagram by author
This is essentially the data structure powering Git repositories, stored right in the .git/objects directory as compressed binary files.
Adding a new commit
Let’s see what happens with a new commit. We will modify hello.txt and add new_file.txt in the second commit.
1
2
3
4
echo "Bye" >> hello.txt
echo "I love git" > new_file.txt
git add hello.txt new_file.txt
git commit -m "Second commit"
If we look at the .git/objects directory and inspect the new Git Objects with cat-file tool, it is possible to manually update the graph.
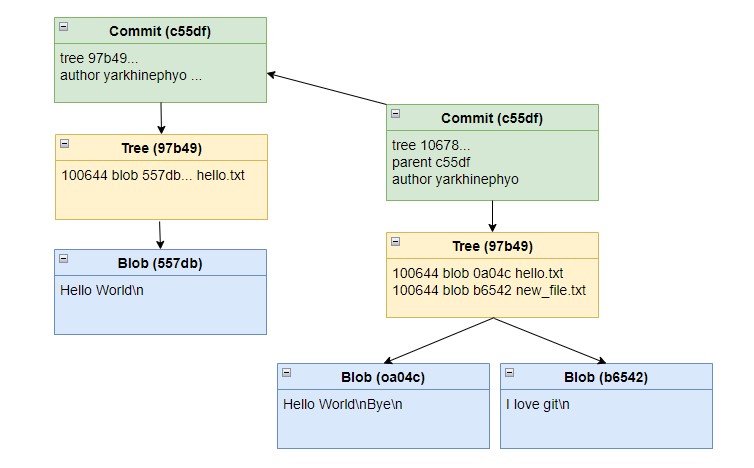 DAG after second commit - Diagram by author
DAG after second commit - Diagram by author
There are two interesting observations.
First, the new Commit has a pointer to the parent Commit in its contents. This means that whatever is in the ancestor Commits affects the SHA-1 calculation of the new Commit. Therefore, as long as we have the SHA-1 calculation of the latest commit, the integrity of Git history can be verified.
Second, a new Blob is created after hello.txt has been modified and a new Tree stores a pointer to it. This is because Git Objects are immutable. Whatever changes made in a new commit would not mutate the previous Git Objects and modify the SHA-1 calculations.
Merkle DAG
This DAG where each node has an identifier resulting from hashing its contents is called Merkel DAG. This data structure also plays an important role in Web3 applications.